Retrieval Augmented Generation (RAG) — Concept, Workings & Evaluation
The large language model (LLM) became a buzzword in 2023. After the massive success of GPT-3, more than one LLM has been released each month. Some popular open-source LLMs are LLaMA 2, Falcon 180B, BLOOM etc. Moreover, the Small Language Models such as Mistral 7B and Phi-2 are also performing surprisingly. Now the community and startups are focused towards how to build more intelligent AI applications especially those related to Natural Language Processing (NLP) by using LLM.
If you are from AI/ML background then you may know that LLM models are transformer (encoder-architecture) architecture trained on huge text datasets and can perform general-purpose language understanding and generation. However, it is very challenging to collect such massive datasets, set high computing resources for training, and perform Reinforcement learning from human feedback (RLHF). Once, LLM is trained, it will understand and generate the response only for the knowledge that it has been trained, but it can’t perform well and starts to hallucinate on information/data it hasn’t been trained before. To incorporate the external knowledge sources to LLM we can apply following two approaches:
- Fine-tuning LLM: Fine-tuning is a process of retraining LLM on smaller custom datasets. However, it requires high computing power and it couldn’t perform well if new data comes in. We need to fine-tune it again once new data comes in. You know, it is not the best solution at all.
- Retrieval Augmented Generation: Retrieval Augmented Generation(RAG) is the process of retrieving information from external knowledge sources with the help of LLM. Here, we retrieve the relevant information from external knowledge bases before answering questions with LLMs. RAG has been demonstrated to significantly enhance answer accuracy, and reduce model hallucination, particularly for knowledge-intensive tasks.
From above approaches, we will use RAG to retrieve knowledge from an external knowledge base by introducing domain-specific knowledge. Now, let’s talk about RAG architecture. Generally, RAG has two main components: indexing and Retrieval and generation. Let’s deep dive into how the above components work.
- Indexing: In indexing data is loaded first using Document loaders, and we split document data into smaller chunks using text splitters. Then, embeddings of chunks are calculated using the Embedding generation language model and are finally stored in a vector database. The following diagram shows the indexing component in the RAG pipeline.

Here, we load our data first, the data might be in different forms such as PDF, JSON, CSV, HTML etc. Then, we split texts from our loaded documents into smaller text chunks. We split documents into chunks because it reduces the cost of retrieval and generation by searching information quickly in smaller chunks. In the embedding generation step, we will calculate the embedding vector of each chunk which represents the context of chunks. Here, we can use different embedding generation models, such as Sentence-BERT, OpenAI ada-002, bge-small and many more. Finally, we store embeddings in a vector database such as Chroma, Pinecone, Weaviate, Milvus etc.
2. Retrieval and Generation: In the retrieval and generation step, the user query is taken as input and we retrieve the relevant contexts from our documents and feed them to LLM along with the user query. Here, we prompt LLM in such as way it gives relevant answers from retrieved contexts. Let me explain in more detail using the following picture.
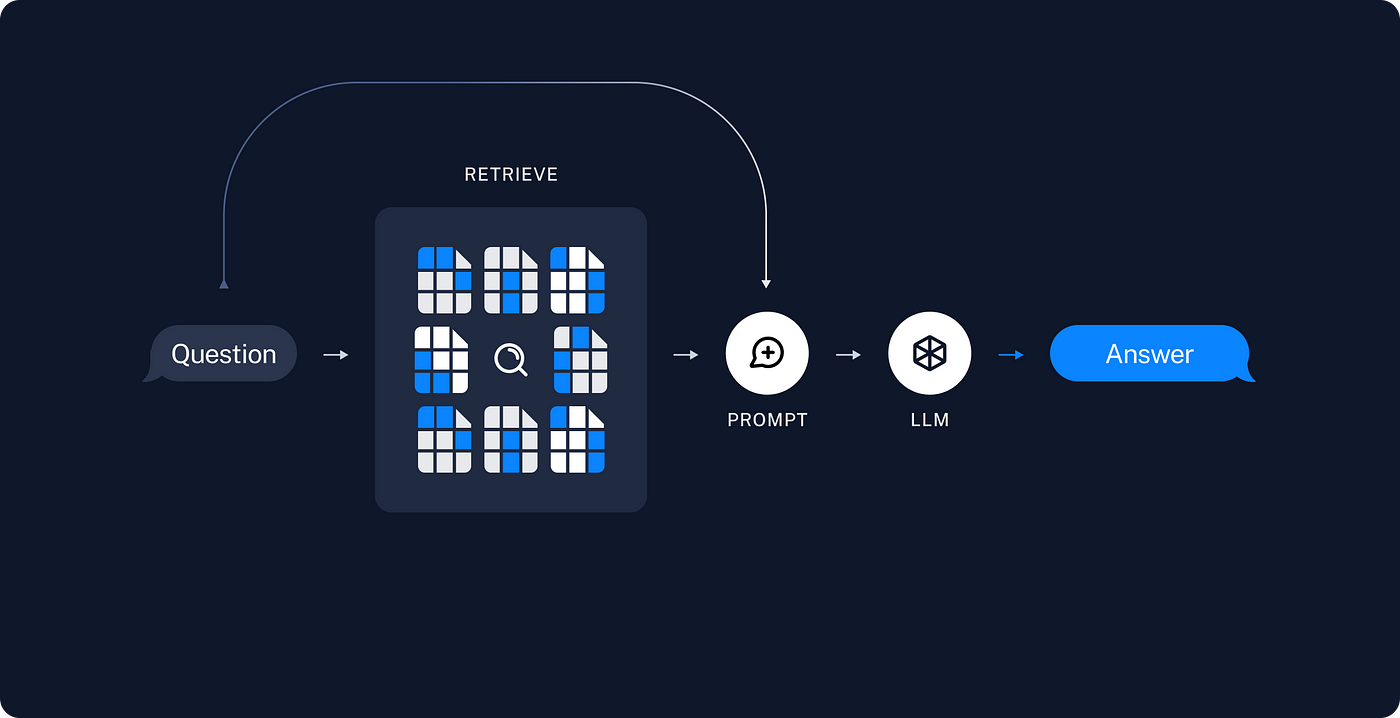
When the user queries on the system, then we calculate the embedding of the user query using the embedding generation model (the same model, that we have used to calculate text chunks embedding during indexing). Then, query embedding is searched on a vector database(where all the chunks embedding has been stored during indexing). Here, top-k chunks that have similar contexts to user queries will be retrieved as the search results. After retrieving the contexts from the vector database, we prompt LLM in such a way that it takes user queries as a query and retrieved contexts as the place to search the relevant information for the user query. Finally, LLM gives a response to the user query by incorporating and evaluating the information from the document uploaded by the user.
Following working diagram clearly demonstrate how both indexing and retrieval & generation componets comprises the Retrieval Augmented Generation (RAG) system.
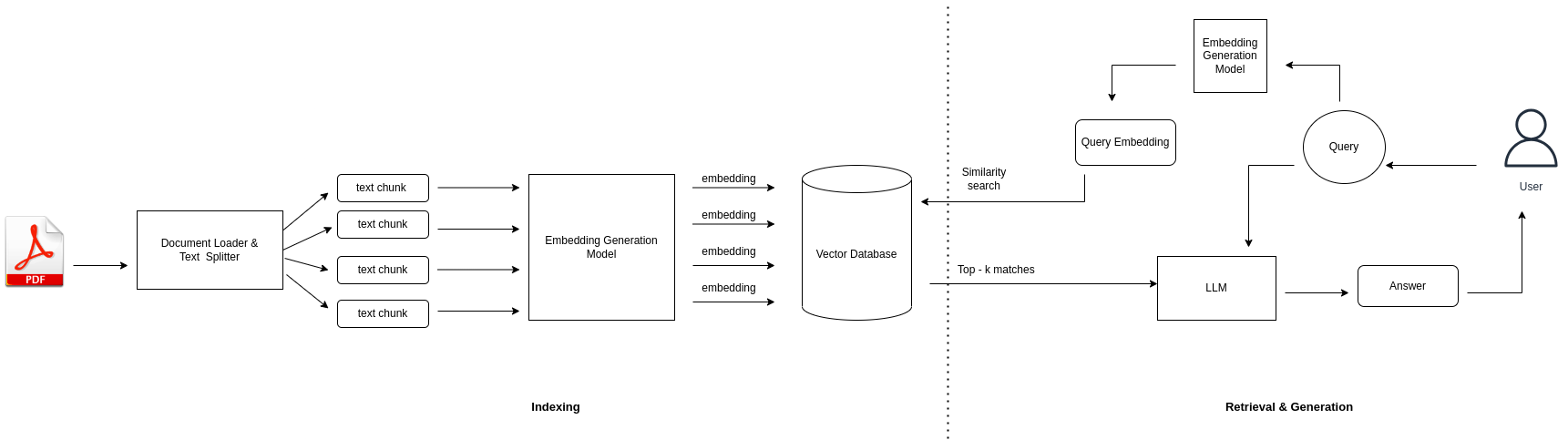
Now, you become familiar with RAG working architecture from document upload, query and final response. But, getting response for your query is not sufficient, we need relevant answer from our document. To ensure that RAG is working correctly, we need to evaluate the performace of RAG. There are multiple evaluation metrices which can be used to evaluate the RAG performace. Here, I will explain three mostly used RAG evaluation metrices:
i. Context Relevance: Context Relevance evaluates whether the retrieved contexts from the vector database are relevant to user query or not. If the contexts retrieved are relevant to user query, then we can ensure that retrieval component is working perfectly fine.
ii. Groundness: Groundness evaluates whether the LLM has maintained same contexts as retrieved from vector database or not.
iii. Answer Relevance: Answer relevance evaluates whether the RAG pipeline provides the response relevant to user query or not.
In conclusion, RAG has been demonstrated to significantly enhance answer accuracy, reduce model hallucination, particularly for knowledge-
intensive tasks. By citing sources, users can verify the accuracy of answers and increase trust in model outputs. It also facilitates knowledge updates
and the introduction of domain-specific knowledge. RAG effectively combines the parameterized knowledge of LLMs with non-parameterized
external knowledge bases, making it one of the most important methods for implementing large language models.
I hope that the above blog is helpful to you to clear your understanding about RAG. If you have any queries I am happy to answer them if possible. If it is helpful to you, then please don’t forget to clap and share it with your friends. See you in next part: Retrieval Augmented Generation(RAG) using LlamaIndex and Mistral — 7B…
